《Visualizing Attention, a Transformer's Heart》笔记
该视频是知名知识博主 3Blue1Brown 推出的 Attention 机制介绍视频。YouTube 视频地址,B 站双语搬运地址。
在本文中,将记录我对该视频的自学笔记,我将在原视频基础之上,补充文字描述和我的理解。笔记中的截图均来自于原视频,在此统一注明出处。
Attention 于 2017 年由《Attention Is All You Need》论文所提出。
Transformer模型的功能:接收一段文字,预测下一个单词是什么。
输入文本首先被分解称小块,称之为 Token。
词向量
首先第一步是词嵌入(Embedding),将每个 Token 映射到高维向量——词向量。

图中每个词表示一个 Token(视频为了展示效果,用单词作为 Token)。
所有可能的 embedding 构成的高维空间(词向量空间)中,方向可以对应语义含义。
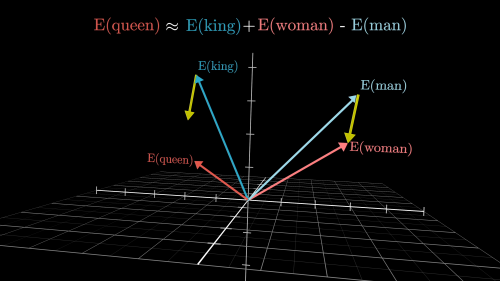
在上图中,是方向对应性别的示例:(
transformer 的目标是逐步调整这些 embedding,使它们不仅仅编码单词本身,而是融入更加丰富、更深层次的上下文语义。
定性理解 Attention
考虑以下短语:
- American shrew code:美国真鼹鼠(mole)
- One mole of carbon dioxide:一摩尔(mole)二氧化碳
- Take a biopsy of the more:对肿瘤(mole) 进行活检
在不同上下文中,mole 的含义不同。
但是在词嵌入部分,三个句子中的 mole 会被嵌入成同一个词向量。因为词嵌入本质上是一个不参考上下文问的查找表:
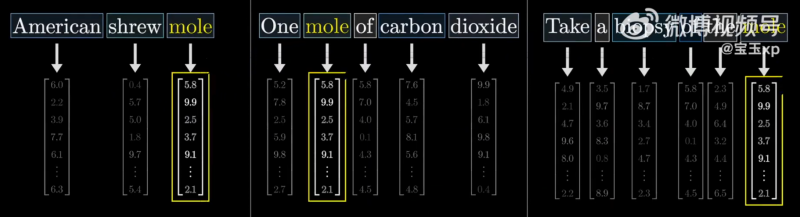
在 Transformer 的下一步, 周围的词向量有机会向这个 Token 传递信息。
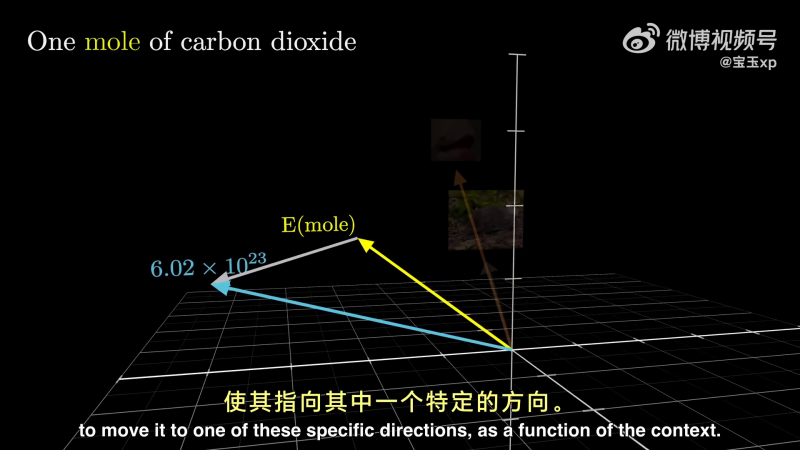
在词嵌入空间中,mole 的几种含义,都有一个向量能够表示。但是 mole 的词向量与他们存在差距。如下图所示:

在一个训练良好的大模型中,Attention 模块就可以计算出,根据上下文信息,需要在通用的 mole 词向量中叠加什么向量,让它指向语义空间中,真正与其语义对应的方向。
Attention 还能将一个嵌入向量的信息传递到另一个向量当中。在下图中,说明这个能力,不仅适用于两个向量距离很近的时候(左侧),更重要的是,当两个向量距离很远时,也依然能够生效:

经过多层神经网络的运算后,用于预测下一个 Token 的计算过程,完全取决于序列中的最后一个向量:
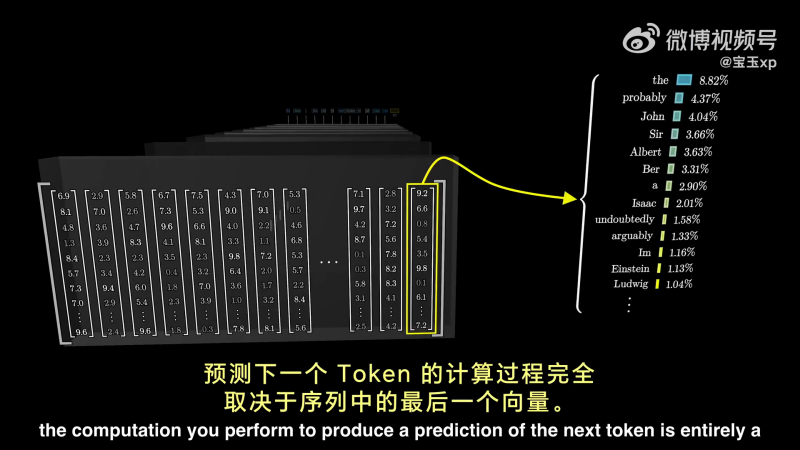
举例来说,如果输入是一整部悬疑小说,在快结尾的地方,写着:“所以,凶手是……”。

如果模型要准确预测下一个词,那么这个序列中的最后一个向量,它最初只是嵌入了单词“是”,它必须经过所有注意力模块的更新,以包含远超过任何单个单词的信息,通过某种方式编码了所有来自完整的上下文窗口中,与预测下一个词相关的信息。

举一个更简单的例子,假设输入是一句话:a fluffy blue creature roamed the verdant forest.(一个蓬松的蓝色生物住在葱郁的森林中游荡。)

假设我们此刻只关注,让形容词调整名词,即:
- 让 fluffy、blue 调整 creature
- 让 verdant 调整 forest
一开始,每个词嵌入向量包含两个信息:
- 是其原始的高维向量,只编码了词的含义,不包含上下文信息。
- 同时还编码了词的位置,位置编码
如下所示:
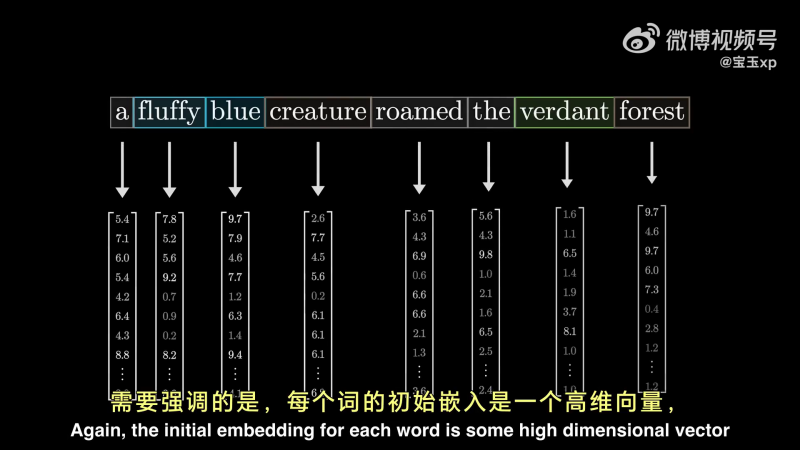
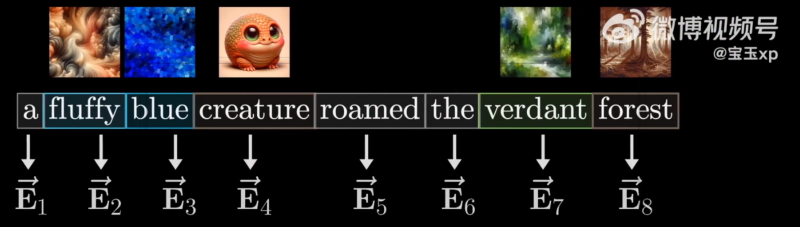
使用字母 E 来表示这些经过位置编码后的词向量:
我们的目标是,通过一系列计算,产生一组新的、更为精细的嵌入向量。可以让名词捕捉并融合了与他们相应的形容词的含义。
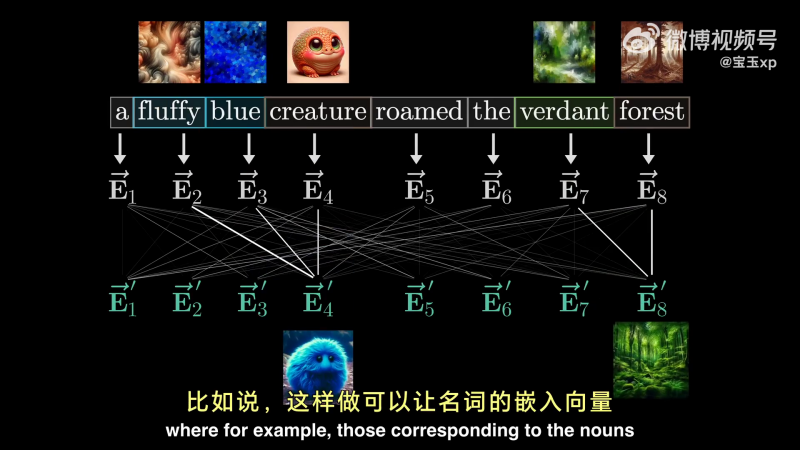
在深度学习中,我们希望将这个过程转换为矩阵运算,并且,矩阵充满了可调权重,模型将根据数据来学习这些权重。

下面详细分析计算流程。以下面这句话中的“creature”为例,它会问:“有没有形容词在我前面?”对于前面的 fluffy 和 blue 会回答:“对,我是一个形容词,我就在那个位置。”

这个问题会被编码称另一个向量,我们称之为 Query Vector:
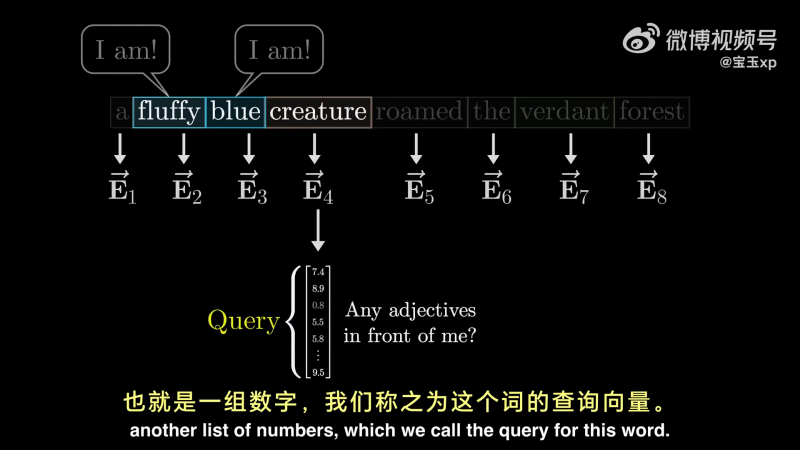
Query Vector 的维度比词嵌入向量的维度要小得多。Query Vector 的计算过程,就是用一个矩阵(
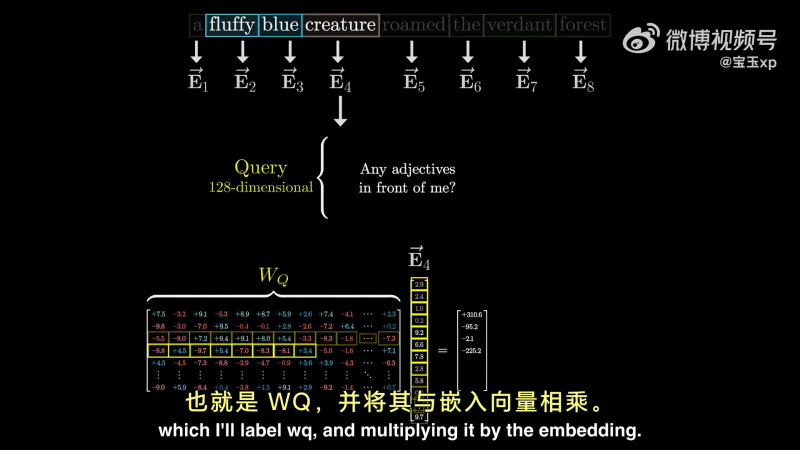
每一个 Token 与
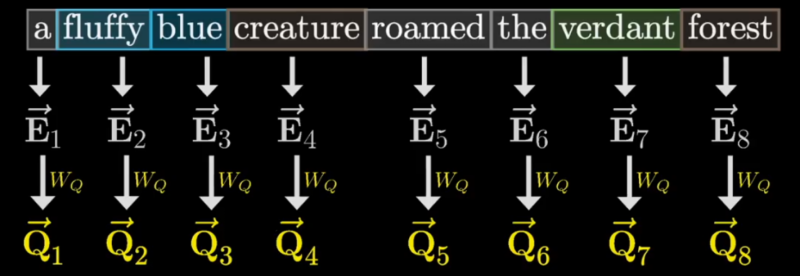
如何理解
除此之外,还有 Key Vector,可以将 Key Vector 想象成潜在的查询回答者。如下所示:

类似于查询矩阵
Query Vector 和 Key Vector 位于同一空间内(Query/Value space),当他们的方向密切对齐时,可以将 Key 视为与 Query 匹配。
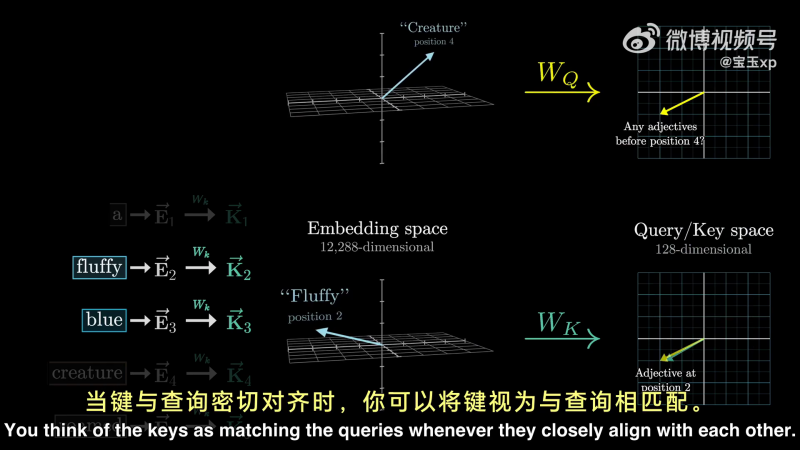
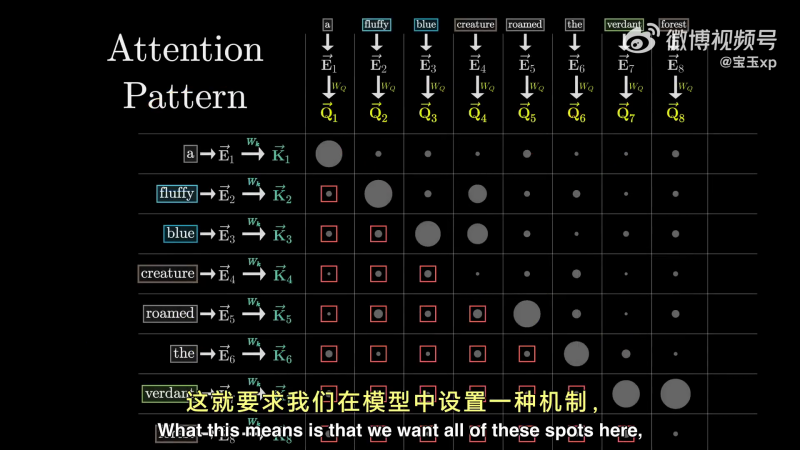
因此,可以通过下图,分别计算点积计算 key 与 query 的匹配程度,用点的大小可视化点积的大小,点积大,说明是 key 与 value 对齐的地方。
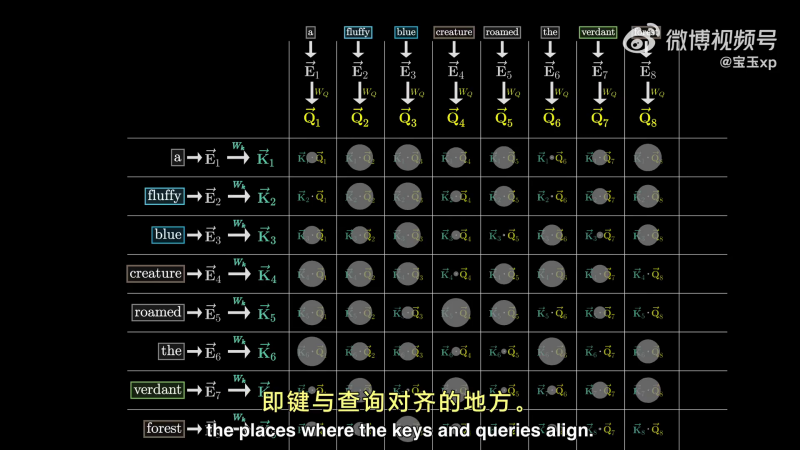
对 creature 来说,fluffy 和 blue 的点积大,按照学术属于,这说明 fluffy 和 blue 嵌入向量会关注(attend to)creature 向量:

这种网格,赋予了我们评估每个单词在更新其它单词含义上的相关性得分的能力。
首先,对每列进行 softmax 归一化。可以将每一列理解为,根据左侧的单词与顶部对应值的相关性赋予的权重。我们将这种网络成为注意力模式(Attention Pattern)。
对应于 Transformer 的论文(《Attention Is All You Need》),他们使用一种非常简介的方式描述这些:
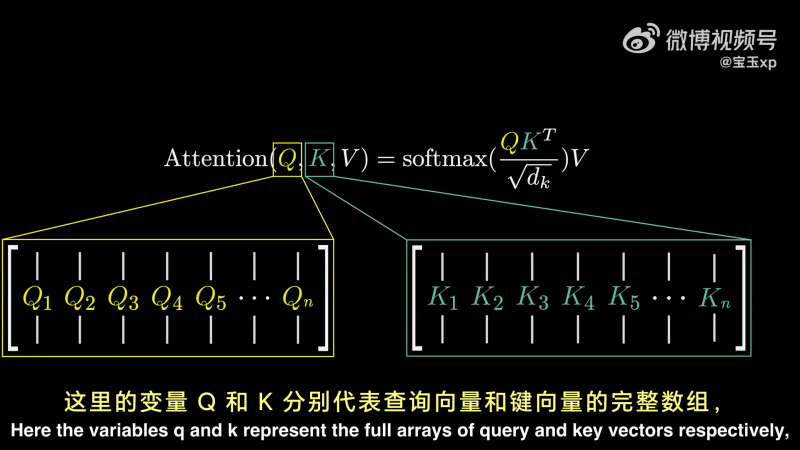
其中,Q 和 K 分别表示 Query Vector 和 Key Vector 的完整数组。这些都是通过将嵌入向量与查询矩阵和建矩阵相乘得到的小型向量。
其中,有一个
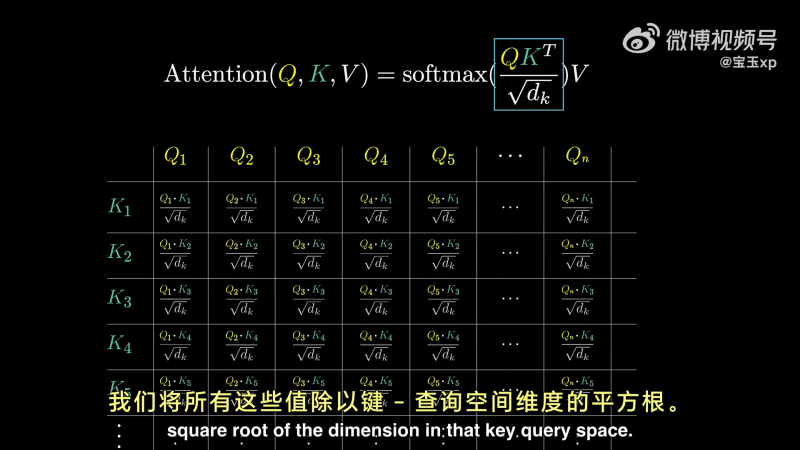
其中的 softmax,我们应理解为按列应用的。
逐 Token 训练
这是一种有效提升训练效果的方法。
给一个训练段落,该段落每个初始 Token 子序列都被拿来进行训练。
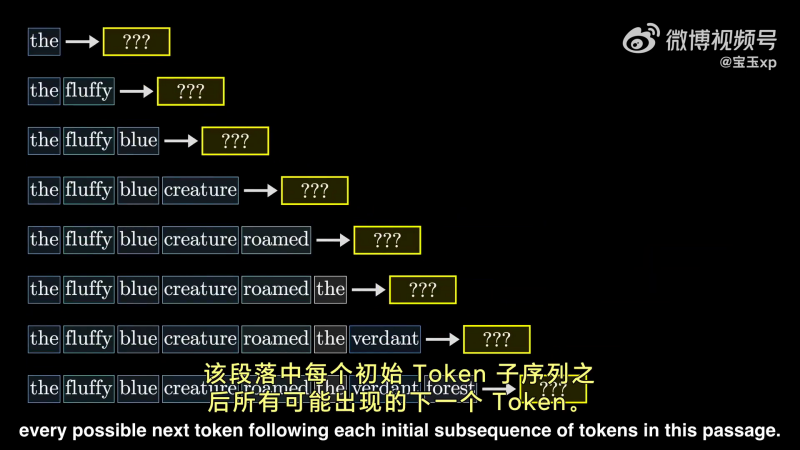
相较于:“一大段话,下一个 token” 这样的训练方式,逐 Token 训练让模型有更多的学习机会,实现了对样本的更加充分利用。
Mask 机制
在设计注意力模式时,一个基本原则是不允许后面出现的词汇影响先出现的词汇。在 GPT 场景下,需要满足这一约束。
因此,需要设计一种机制,屏蔽矩阵中,位于 token 之后的权重,使每个 token 后面的 token 对其不具备影响力:
具体做法是,在 softmax 之前,将下三角阵设置为负无穷,在 softmax 时,对应的权重即可为 0,同时每列相加还能为 1:
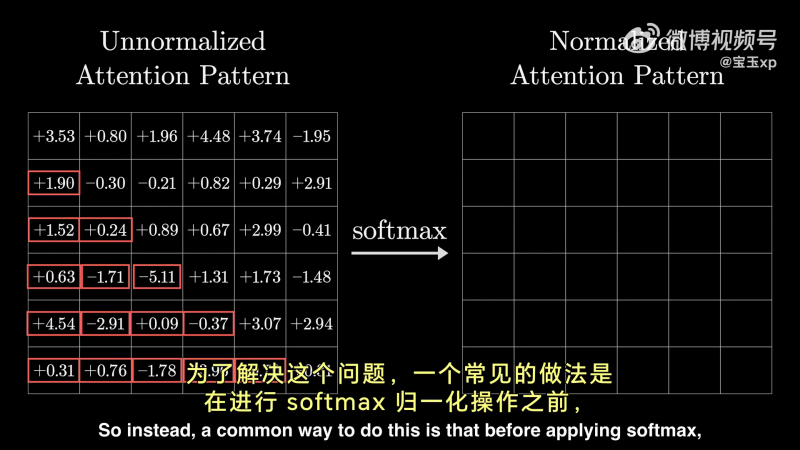
经过 softmax 之后:
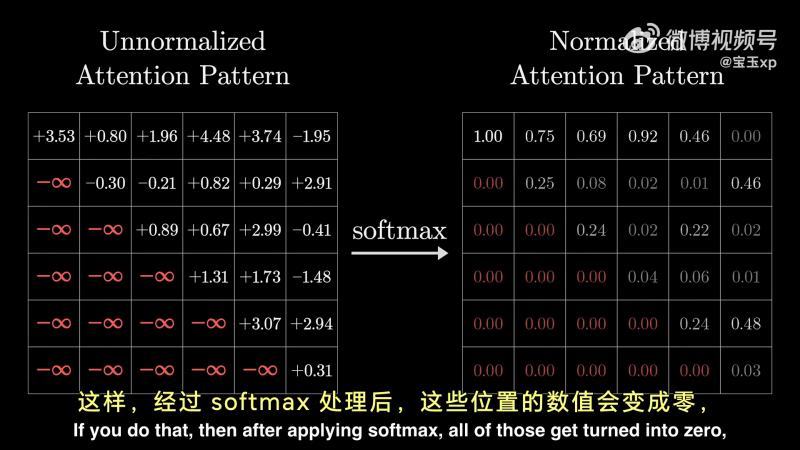
这个过程就叫做 masking。
注意力模式=上下文的平方
上面的这个注意力模式矩阵的大小,与上下文呈平方关系。
这就是上下文大小会对大语言模型形成巨大瓶颈的原因。

近年来,出于对更大上下文窗口的追求,出现了一些对注意力机制的改进:
- Sparse Attention Machanisms
- Blockwise Attention
- Linformer
- Reformer
- Ring attention
- Longformer
- Adaptive Attention Span
- ……
更新嵌入向量
接下来需要实际更新嵌入向量,让词语将信息传递给他们相关的其他词。
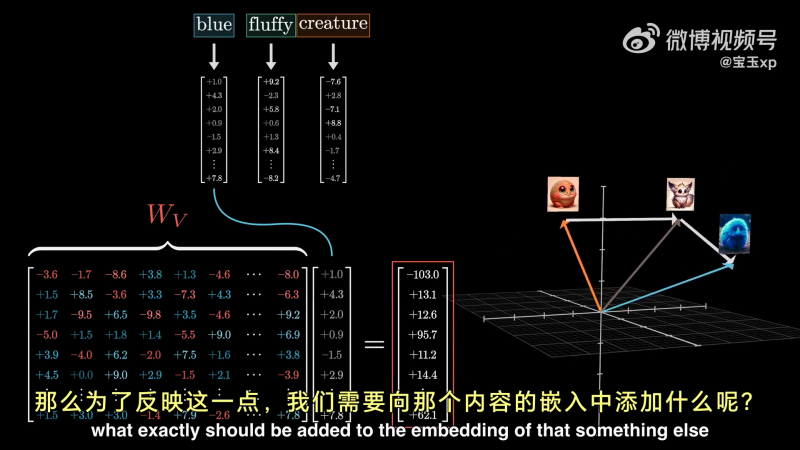
在单头注意力下,使用第三个矩阵值矩阵
首先,每个词都乘以
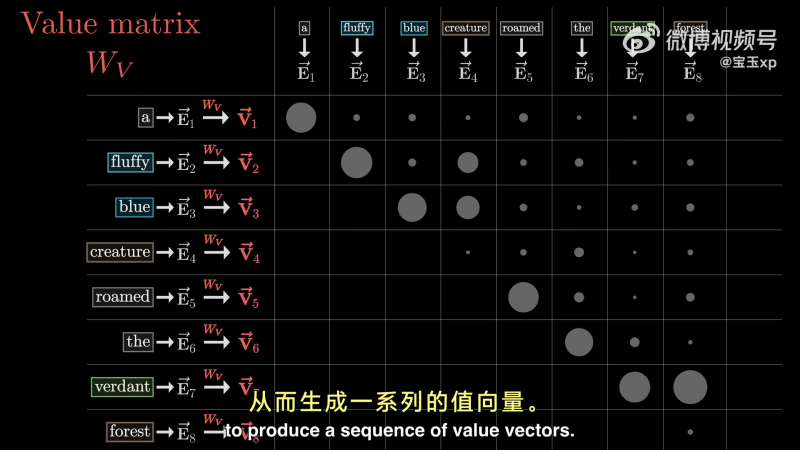
可以将这些值向量(Value Vector)视为在某种程度上与他们对应的“键”相关。
接下来,将每个权重与值向量相乘:
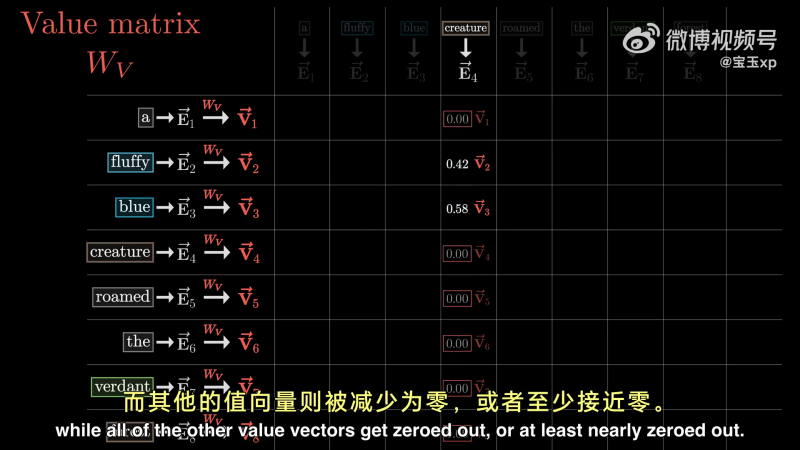
最后,为了更新这一列与之相关的嵌入向量(creature),将嵌入向量与下面这些向量相加(得到一个
在所有 Token 序列上都进行这一操作,便形成一组更为细腻且富含信息的嵌入向量序列:
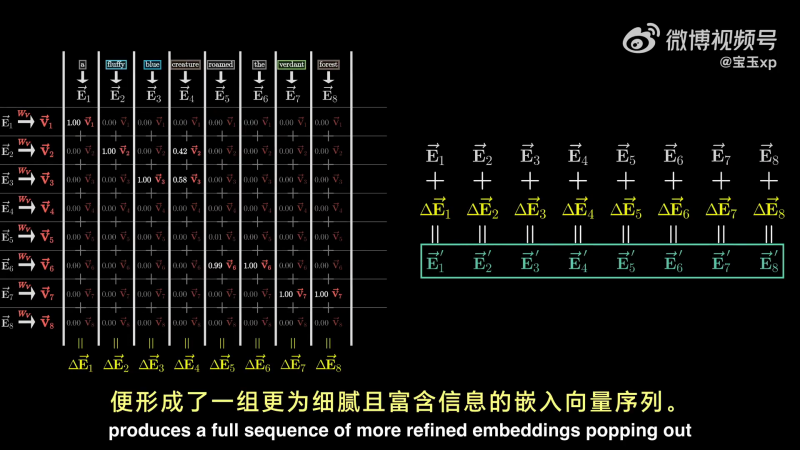
一组操作叫做 Attention Block,构成了所谓的单头注意力机制。
从宏观来说,这一机制通过三种不同的,充满可调参数的矩阵来实现:

模型参数量统计
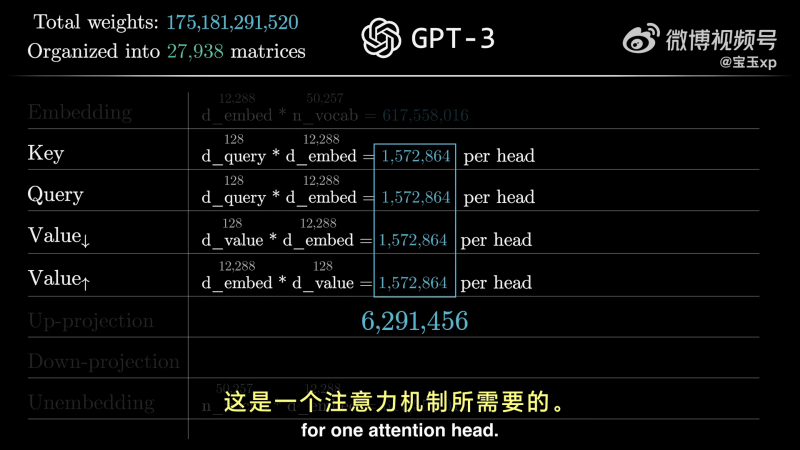
GPT-3 总参数量:175,181,291,520。坐落于 27,938 个矩阵当中。
具体包含的矩阵有:
- Embedding:嵌入维度 12288
- Key:Wk 有 12288 列,与嵌入维度匹配,128 行即 Query/key 空间维度,单个矩阵有 150w 参数
- Query:Wk 有 12288 列,与嵌入维度匹配,128 行即 Query/key 空间维度,单个矩阵有 150w 参数
- Value:方阵,宽高都是 12288,1500w 参数。一种优化方法,是将其拆分成两个更小矩阵的乘积——值降维矩阵、值升维矩阵。
- Output
- Up-projection
- Down-projection
- Unembedding
一个注意力头需要 630w 参数:
多头注意力
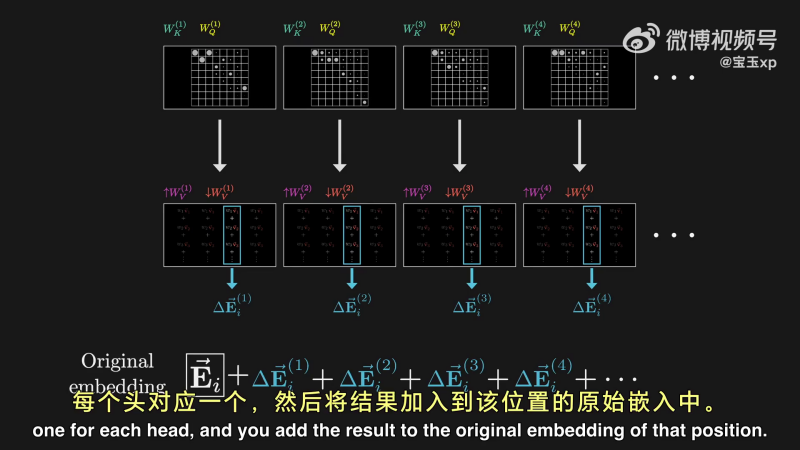
在 Transformer模型中,不仅有一个注意力头,而是多头注意力。他们同时进行上面的注意力操作:

在 GPT-3 中,每个块都使用了 96 个注意力头。
也就是说,每个块有 96 种不同的 Wk、Wq,产生 96 种注意力模式。并且,每个注意力头,都有独特的值矩阵 Wv,用来产生 96 各值向量的序列。所有这些都通过使用对应的注意力模式,作为权重进行相加。
每个头都会产生一个方向调整建议,然后汇总所有建议,对词向量进行叠加:
分层的概念
GPT-3 有 96 层。每一层之间包括注意力模块和多层感知机。
注意力机制的成功之处
并非在于它所启动的任何特定类型的行为,而在于它及其适合并行运算。
这意味着使用 GPU 在短时间内完成大量的计算任务。
本文作者:Maeiee
本文链接:《Visualizing Attention, a Transformer's Heart》笔记
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
